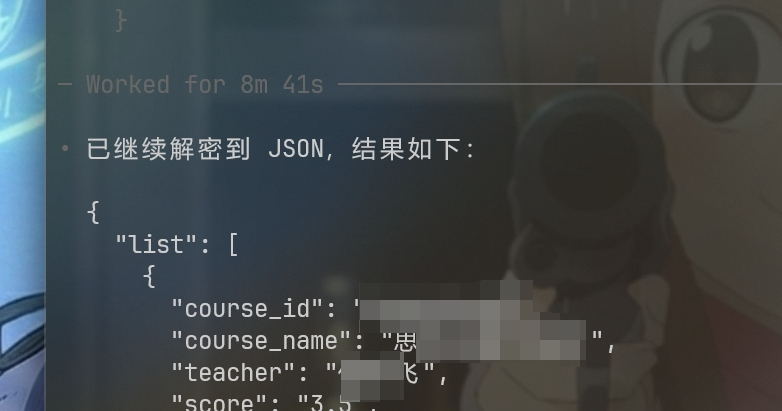
某小程序课程信息逆向过程
前言
某某集市小程序在我们学校是优质的信息来源平台。而且人还非常好,帖子信息都是无加密的,同时用户的token也是长效token,根本不用担心过期。 然后上个月推出了个选课信息板块,一开始也是没加密来着,后面过了几天,发现灰度测试加密了。于是打算研究一下怎么加密的。

解包
尝试了Base64发现还不太能解出来,于是就考虑AES加密了,接下来就要去找iv和key了

这时候就犯难了,小程序不像网页端,不能用控制台调试,不方便找key和iv,而且代码大概率还是混淆的。于是只能先把小程序解包看看,这里使用biggerstar/wedecode: 全自动化,微信小程序 wxapkg 包 源代码还原工具, 线上代码安全审计,支持 Windows, Macos, Linux,这是之前的**UnpackMiniApp**作者新开的项目,还是比较好用的。直接在小程序中搜索,能找到两个AES的key。
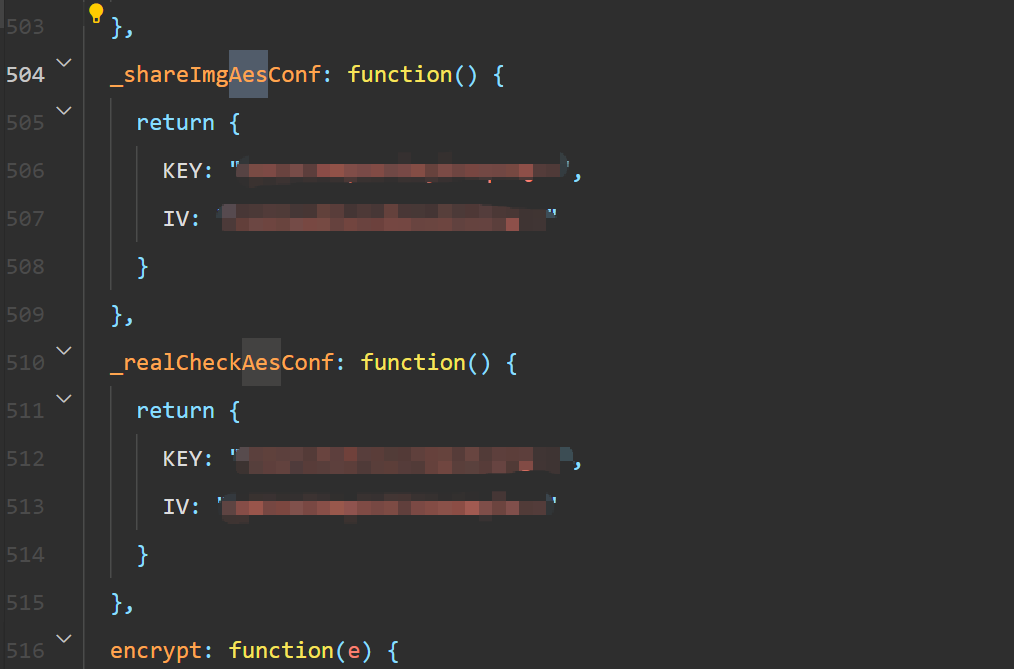 但是从名字上看,这俩就不像是那个接口用的密钥;并且全局搜索也搜不到这个这个接口的调用的地方,这就很抽象了。难道是静态文件压缩成wasm传输走的ws。这样的话抓包也抓不到js了。
但是从名字上看,这俩就不像是那个接口用的密钥;并且全局搜索也搜不到这个这个接口的调用的地方,这就很抽象了。难道是静态文件压缩成wasm传输走的ws。这样的话抓包也抓不到js了。
破局
小程序解包卡住之后,回去看了抓包记录,发现有意思的地方,原来这个课程评价页面是内嵌的h5页面,这就简单了,我只要抓到链接,放到浏览器里就随便调试了,不过直接把链接和cookie放到浏览器里,发现还是打不开。
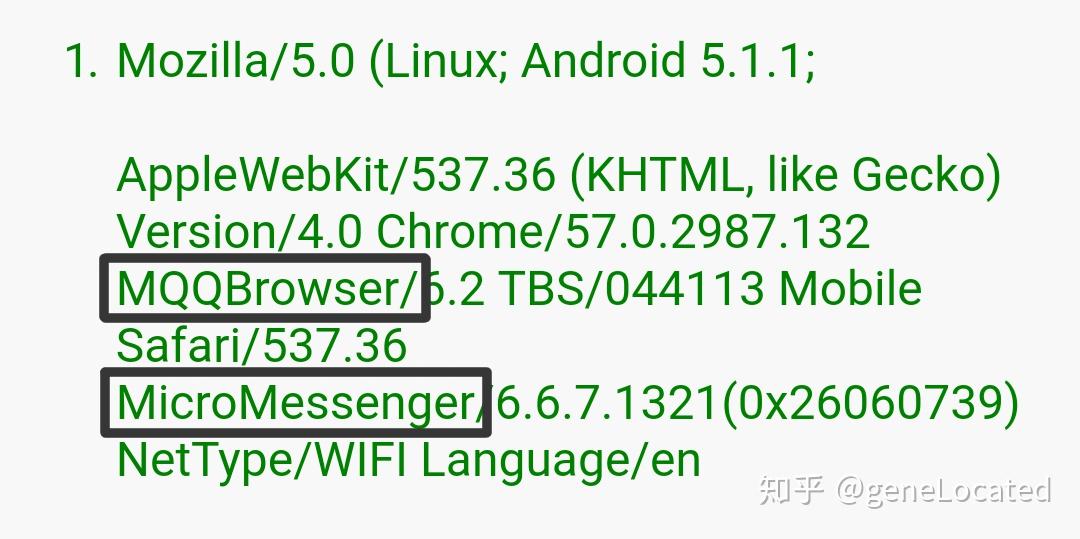
后来搜索了一下,发现要把UA设置成MicroMessenger(微信内置浏览器)就可以了
调试
接下来这个调试就简单了,打断点,定位,这里就不赘述了。现在gemini都要100万上下文,读这些混淆代码很简单了
我这里用的antigravity来逆向这个算法,不过gemini给我改了好多版都是错的,最后折腾一晚上,换了0ai的codex十分钟直接秒了,用了100行代码就复刻了逆向代码,还得是codex啊。下面给出AI总结的解密过程,确实有点复杂。
可以,把它当成“三层套娃解密”:先把一段 URL/BASE64/AES 的外壳拆掉,拿到第二层的“动态密钥 + 数据”,再做一次类维吉尼亚解密,最后用一张“字符→6bit”的映射表把文本还原成 JSON。
整体流程(从输入到 JSON)
0)输入预处理
decrypt_layer1() 里第一步:
unquote(encrypted_text):把 URL 编码还原(比如%2F变/)。base64.b64decode(decoded):把它 base64 解成 bytes。data_bytes.decode(... )得到字符串data_str。- 再
base64.b64decode(data_str):又解一次 base64,得到 AES 的密文cipher_bytes。
所以输入是 URL 编码 + base64 包裹,里面又是 一个 base64 字符串,最终才是真正 AES 密文。
第一层:AES-CBC 解密(固定种子“变形”得 key/iv)
1)key / iv 怎么来的?
不是直接写死 key/iv,而是用 vigenere_decrypt() 从两个常量里“解”出来:
key = vigenere_decrypt(SEED_KEY_ENCRYPTED, DECRYPT_DICT)iv = vigenere_decrypt(SEED_IV_ENCRYPTED, DECRYPT_DICT)
这里的 vigenere_decrypt() 做的事是:
- 把
SEED_*当 base64 解码成 bytes - 对每个 byte,减去
dynamic_key(字符串)的对应字符 ASCII 值(循环用) - 得到字符拼成结果字符串
所以这是一个“按字节减 key 字符 ASCII”的自定义维吉尼亚变体(不是传统字母表那种)。
2)AES 解密本体
AES.new(key, AES.MODE_CBC, iv)cipher.decrypt(cipher_bytes)
注意它这里如果密文不是 16 的倍数,会补 \0 到 16 对齐:
1 | if len(cipher_bytes) % 16 != 0: |
这不是标准 padding(比如 PKCS7),更像“容错补齐”。
输出得到 layer1(utf-8 decode,ignore 错误)。
layer1 的结构:l2_key + SEPARATOR + l2_data
它要求 layer1 里必须包含:SEPARATOR = "%%%%@@@@@%%%%"
然后:
1 | l2_key, l2_data = layer1.split(SEPARATOR, 1) |
l2_key:第二层解密要用的“动态 key”(每条密文都可能不同)l2_data:第二层密文(字符串形式)
第二层:再做一次 vigenere_decrypt(动态 key)
1 | layer2 = vigenere_decrypt(l2_data, l2_key) |
同样逻辑:base64 decode → byte - ord(key_char) → 拼成字符。
此时得到的 layer2 还不是最终明文,它更像是一段“用特殊字符集编码的文本”。
第三层:自定义 6-bit 字符映射 → bytes → 文本
1)先拿到 map_string(字符表)
map_string 不是写死的,也被 vigenere_decrypt 解出来:
1 | map_string = vigenere_decrypt(MAP_SEED_ENCRYPTED, MAP_SEED_KEY) |
你可以把它理解成一个“字母表”,长度大概率是 64 左右(因为后面是 6bit)。
2)custom_binary_decode()
核心逻辑:
- 去掉
=padding - 对
layer2中每个字符:- 在
map_string中找它的位置idx - 把 idx 变成 6 位二进制
format(idx, "06b") - 拼到
binary_str
- 在
然后:
- 把二进制串裁成 8 的倍数
- 每 8 位转成一个 byte
- bytes 用 utf-8 decode 得到
final_text
这一步本质上就是:用 64 字符表把文本当 Base64 那样解码,但字符表是自定义的,而且实现方式是“找索引→转二进制→拼 bytes”。
解密效果