解决报错RuntimeError: GET was unable to find an engine to execute this computation
起因
三个月前,写了个项目,将三个模型糅合进一个后端进行调用,同时做成即插即用式。三个月后现在,当我运行项目后端时,竟然报错了。仔细一看我还以为是显卡爆炸了。
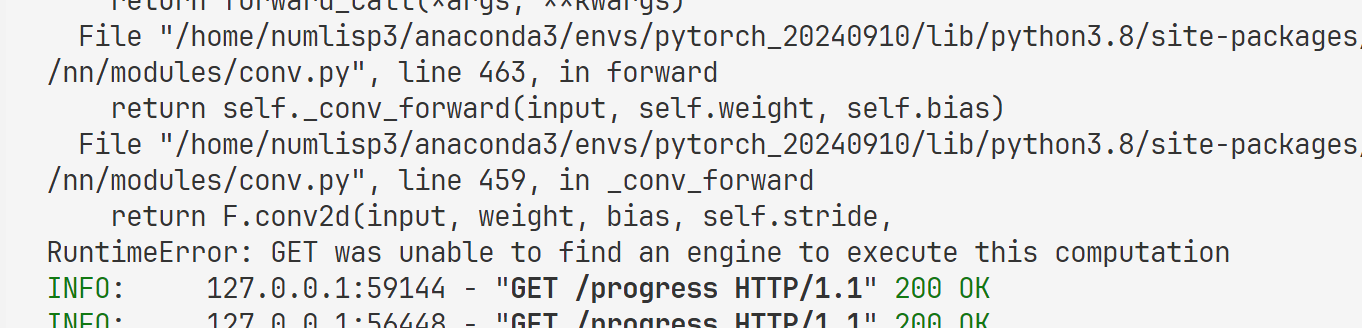
集成的三个模型都出现这个问题,网上的解决方法大部分都是说,数据和模型不在一个设备上,即cuda和cpu,但是排查了一下,不是这个原因。师兄的conda环境还能正常跑,而我的就报这个错,十分的诡异。于是在网上高强度冲浪,终于找到了原因Debug系列:pytorch报错GET was unable to find an engine to execute this computation
打开python交互命令行,使用下面代码会发现:
1 | import torch |
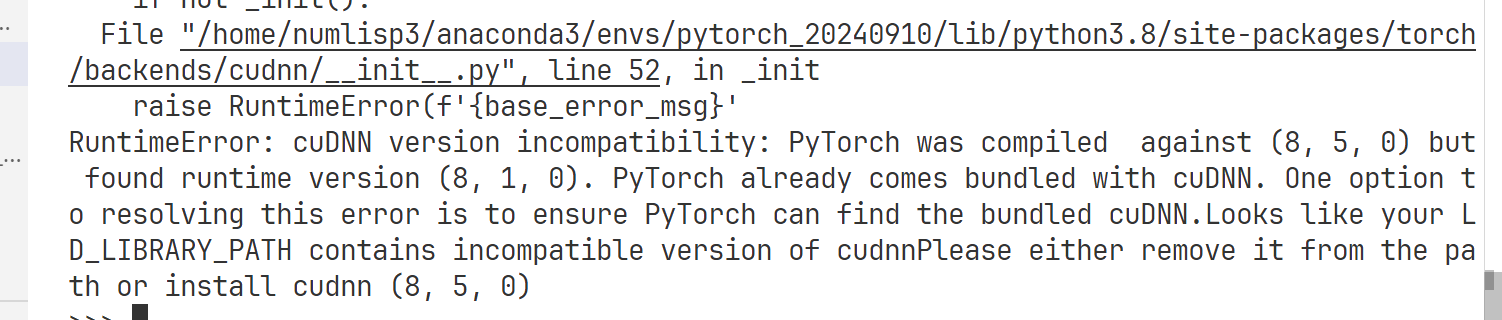
原来是师兄之前装了个新的cudnn,装到全局环境了。导致我的conda环境读到了环境变量中的全局cudnn
解决方法
最简单的解决方法就是
1 | unset LD_LIBRARY_PATH # 取消cudnn的环境变量 |
或者在.bashrc中就把这个环境变量unset掉,但是秉持修旧如旧的思想,还是不要改这个好,只针对我自己的环境,写个激活脚本就好:
1 | cd ~/anaconda3/envs/{env_name}/etc |

相关推荐






评论


